 |
This post is part of the CAP theorem series. You may want to start by my post on ACID vs. CAP if you have a database background but have never really been exposed to the CAP theorem. The post discussing some traps in the ‘Availability’ and ‘Consistency’ definition of CAP should also be used as an introduction if you know CAP but haven’t looked at its formal definition.
|
CAP is a theorem, but it is also widely used to categorize distributed systems and to explain their trade-offs. It looks great: “Hey, it’s based on a theorem! This is scientifically proven!”
However, the meaning of these categories--AP, CP, CA--is not that clear, leading to an opposite result: the CAP categorization says very little on how the distributed system actually behaves. For example, look at the CA category--Consistent and Available but not Partition-tolerant. A widely accepted opinion is: “Partition cannot be avoided. Your distributed system can just choose to sacrifice either consistency or availability when a partition occurs. So a distributed system cannot be CA, by definition.” Indeed, Eric Brewer himself, wrote in 2012 [C3]: “Does choosing consistency and availability (CA) as the ‘2 of 3’ make sense? As some researchers correctly point out, exactly what it means to forfeit P is unclear.” Should one use the CA category then?
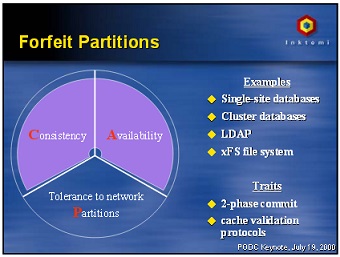
A slide saying that some systems are CA. Does
its author really understand CAP?
To answer this question, we’re going to use CAP to categorize a few different distributed systems:
- A simple application using a single server with a traditional SQL database.
- The same application, but with an Eventually Consistent store instead of our traditional SQL one.
- An application using multiple databases and the two-phase commit protocol.
- A distributed consensus server, like Apache ZooKeeper or Google Chubby.
Also, as we know, using CAP in a database context can be confusing. In this post, I always use CAP terminology and not ACID terminology. When I say “consistent” or “strongly consistent”, it’s always for the consistency-as-in-CAP. Same for “available”: it always means available-in-CAP.
CAP - the usual reminder
CAP says that a distributed system cannot be Consistent, Available and Partition tolerant.
Here we will use the definitions from the proof of the CAP theorem by Gilbert and Lynch [C2]. They are important. Many CAP misunderstandings come from using very intuitive but very wrong definitions.
Consistent is [C2]: “Atomic, linearizable, consistency [...]. There must exist a total order on all operations such that each operation looks as if it were completed at a single instant. This is equivalent to requiring requests of the distributed shared memory to act as if they were executing on a single node, responding to operations one at a time.”
Available is [C2]: “For a distributed system to be continuously available, every request received by a non-failing node in the system must result in a response.”
Partition is [C2]: “The network will be allowed to lose arbitrarily many messages sent from one node to another. When a network is partitioned, all messages sent from nodes in one component of the partition to nodes in another component are lost.”
A simple database application and CAP
Let’s look at a very simple application, distributed on two nodes with a traditional SQL database. The (made-up) specification of this application is: “This application allows you to fill and save forms in a web browser. It needs a database to run.” The deployment is simple: on one machine, a web-server; on a second one, an Relational Database Management System (RDBMS, i.e. a traditional database offering ACID properties). Between the two, a network. The web-server reads and writes from the database.
Is this a CP or an AP application? Well, when there is no partition, we are strongly consistent. When there is a partition, we are not available at all, so we remain consistent. As a consequence we are CP.
That “not being available at all is enough to be CP” can be surprising, but is actually mentioned in the proof itself [C2]: “If availability is not required, then it is easy to achieve atomic data and partition tolerance. The trivial system that ignores all requests meets these requirements.”
If you are strongly consistent before the partition, and not available after, you are CP. For this application a partition does not lead to a choice between ‘A’ and ‘P’ but leads to an immediate shutdown of the overall service. This, by the CAP theorem, means CP. Obviously, most trivial applications are CP.

Most pictures on the Internet are cat pictures. And most
distributed systems you find there are CP.
The same application with an Eventually Consistent store
What is the importance of using an RDBMS in this application?
After the partition it is not important at all. The application is not available because it cannot access the database. The consistency model of this database has no importance at this stage.
Before the partition it is important for our classification: if, when there is no partition, the application is not strongly consistent then it cannot claim to be CP. So, if instead of using an RDBMS the application stores its data in an Eventually Consistent store, the system as a whole is not CP. What is it then? Let’s see what we have:
- CP: no, because the application is not strongly consistent.
- AP: no, because the application is not available during a partition.
- CA: no, because the application is not strongly consistent.
So this application is nothing from a CAP point of view. It would still be a valuable application, maybe more fault-tolerant than the one using an RDBMS, but it still wouldn’t fit into any CAP category. Using an Eventually Consistent store but being unavailable during partition puts you out of the CAP categorization.

Some Distributed Systems Are Not to be Named
(by CAP at least)
CP and ACID-Consistency
Strictly speaking, the reliability added by the database, typically an RDBMS, is not important when looking at the CP category: even if the database is corrupted during the partition and the application cannot be restarted when the partition is fixed, it would still be in the CP “partition-tolerant” category. It is an extreme case, but it shows that using an RDBMS does not impact the “partition-tolerance” of the categorized application. What matters is the behavior before partition and the fact that the application is not available during partition.
Applications using two-phase commit with SQL databases
The objective of the 2 phase-commit (2PC) is to have a single ACID transaction on multiple nodes, whatever happens (read: failure and partition). So we have a distributed system with multiple databases and multiple clients. These clients can do simple transactions--going to a single node--or distributed transactions--going to multiple nodes. Transactions going on multiple nodes will use the two-phase commit protocol.
Here is a simplified description of how the two-phase commit works:
- the transaction starts on multiple nodes. One of the nodes is the coordinator.
- during the first phase, the coordinator asks all nodes if they can commit the transaction. This means they have the resources available (enough disk space for example), that all the integrity constraints are valid and so on. All the nodes must send their result back. If they say “yes” at this stage, they cannot change their minds later. So they need to keep all the resources available, locks included. Again: they are not allowed to fail or rollback once they have replied “yes” to the coordinator.
- if one of the nodes says “no”, the coordinator asks for a rollback on all nodes and we are done.
- if all the nodes say “yes”, the coordinator asks all nodes to commit their part of the transaction and we are done.
Two-phase commit with partition
That looks simple. But what happens if there is a partition between the database nodes during the commit phase? Then, one or more of the nodes may not receive the final decision from the coordinator. The node can choose between holding all locks and resources (i.e. being not available) or taking a local decision. This local decision is called an “heuristic decision”. This means the node either commits locally or rollbacks locally, but does something and does it independently from the others nodes.
In CAP terms, heuristic decisions are here to improve the availability: instead of locking indefinitely, it continues. But there is no free meal, and this increased availability comes with a drawback. Here, different nodes can take different decisions: one node can commit half of the transaction, while the other node can rollback its second half. For example, if you are using two-phase commit to book a single round-trip ticket with two different airline companies, you may end up with half of the flight booked.
This is a known issue. For example, the jboss documentation says: “It is one of the worst errors that may happen in a transaction system, as it can lead to parts of the transaction being committed while other parts are rolled back, thus violating the atomicity property of transaction and possibly leading to data integrity corruption.“ As this documentation says, we broke the Atomicity-in-ACID property of the transaction. In our example, we can also consider we broke the Consistency-in-ACID: a round-trip ticket should have two flights attached but we have only one.
So heuristic decisions in the two-phase commit increase the availability by making the transaction non-ACID. But what are we from a CAP point of view? Are we CP or AP?
Categorizing the two-phase commit
The easy part first: any operation involving the two nodes is no longer possible. So, obviously, the system is not available-as-in-CAP: some (but not all, and that’s the whole point) operations will fail, and the ‘A’ of CAP does not allow this. So this system is not AP.
Are we CP? Neither, because there are some scenarios that will show an incoherent history. For example in our flight application, we may imagine a single transaction doing this:
- store the first flight in node A.
- store the second flight in node B.
- store the whole ticket, with references to the two flights, in node A.
If node A commits and node B rollbacks, node A sees a history that does not exist: the second flight existed and disappeared. That’s not consistent-in-CAP.
So we’re not AP, and we’re not CP. We now have the choice between “Is Not To Be Named” and CA. Let’s try CA first.
The unclear case for CA
What about using CA here? That was the point of view of the author of the slide used in the introduction. Here it is again:
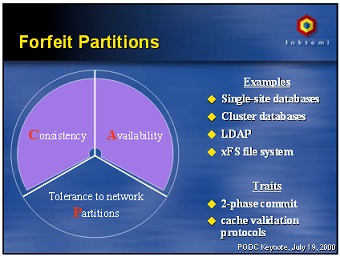
Slide from Eric Brewer’s presentation
of the CAP conjecture in 2000
We know that we cannot avoid network partition. What if we specify our application like this: “this application does not handle network partition. If it happens, the application will be partly unavailable, the data may be corrupted, and you may have to fix the data manually.” In other words, we’re really asking to be CA here, but if a partition occurs we may be CP, or, if we are unlucky, both not available and not consistent.
Saying this implies that CA and CP/AP are not about the same face of a distributed system:
- CA is a specification of the operating range: you specify that the system does not work well under partition or, more precisely, that partitions are outside the operating range of the system.
- CP or AP describes the behavior: what happens if there is a partition.
We could draw a parallel with the specification of a software. Let’s imagine a simple application written and tested with Postgres, and then the dialogue between a software vendor and his customer:
 |
Here is the application you paid for. It works on Postgres.
| ||
Thanks, but I’m running Oracle here.
|  | ||
|
We don’t have a license for Oracle. We can’t support you on this platform. It’s clearly specified, see page 327 of appendix E.
| ||
(time goes by)
| |||
FYI: I did some tests on Oracle, it seems ok. It goes in production tomorrow. I will let you know if I have any issues.
| | ||
|
But we won’t be able to fix them!
| ||
This you will have to discuss with our lawyers. But I tested many cases, I’m confident it works well enough.
| | ||
At the end of the day, does this application work on Oracle or not?
You can look at a software by its specification or by its actual behavior. They sometimes diverge. And the specified operating range may be applied or not. Depending on the importance of the application, you may offer a degraded mode, or a repair tool, or go crazy, or hope for the best, or whatever.
In the case of a distributed system, you can specify that you don’t handle well network partition. It does not prevent network partition to happen, it just says that network partition could break all or some parts of the software promises.
From this point of view, the two-phase commit is CA: it tries to minimize the probability for a partition to have an impact on the system. However, if this happens, the behavior is documented.
CA and CP overlap because they do not describe the same face of a distributed system. CA specifies an operating range. CP/AP describes what happens during partition, even if partitions are outside the operating range.

The CA category does not belong to the same world
as the CP and AP ones.
Distributed Consensus Server
A typical example of such an application is Chubby [V4]. Consensus systems are typically used to agree on a unique value of a data between distributed nodes. These nodes can fail or be partitioned.
Chubby has the following characteristics:
- It contains 5 nodes.
- A master is elected. It must get at least 3 votes: this is called the quorum.
- All reads and writes go through the master.
- If the master fails, a new election takes place.
- Clients can go to any node. If they go to a node that is not the master, this node will redirect them to the master.
This is a simplified view: for example, there can be fewer or more nodes. The heart of this mechanism is the vote. Chandra and al. proved that these systems work and and will continue to work if there is a partition or a crash of a minority of servers [V3]: the master can be elected if there are 3 voters, so the protocol tolerates the failure or the partition of 2 nodes.
Is this available? No, because of the definition of availability in [C2]: “every request received by a non-failing node in the system must result in a response.” If there is a partition, some nodes will be non-failing, but will not be able to fulfill any query they receive. CAP is about being fully available: all nodes must continue to serve all queries. CAP does not make any difference between responding on some nodes and not responding at all: these two system types belong to a single CAP category, CP.

Some cats are more expensive than
others, but they are still cats.
Conclusion
Using the CAP theorem to categorize CA and CP distributed systems shows:
- CAP lacks some categories: some valid systems may be “non-consistent-in-CAP” and “non-available-in-CAP”, especially because of the highly demanding definition of availability in CAP.
- Partition does not always imply a binary choice between availability and consistency. Other choices are possible (Eric Brewer said this already [C3]). However, these choices put you out of the CP/AP categories, because Availability-in-CAP means “all nodes” and “all requests”.
- Using CA can be “not clear” but is not ridiculous. I’m personally happy to consider it as the specification of an operating range, with CP/AP being the description of a behavior.
- CP catches more than it should. It catches:
- Applications “consistent” and “partly available” during a partition.
- Applications “consistent” but “not available” at all during a partition. One could consider that these applications are actually CA: they could specify that they do not handle partitions.
- Applications breaking their “consistency-in-ACID” constraints during or after a partition. One could consider that these applications are actually CA: that’s the two-phase commit example.
 |
This post is part of the CAP theorem series
| |
References
[C2] Gilbert and Lynch. Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services. ACM SIGACT News (2002)
[V3] T. D. Chandra and S. Toueg. Unreliable failure detectors for reliable distributed systems. Journal of the ACM, 43(2):225–267, 1996.
Cross posting my notes from HN in case you aren't reading comments there:
ReplyDeleteFirst, in the "The same application with an Eventually Consistent store", you don't actually define the semantics of the system, so there is no way to say how it relates to CAP. Eventually consistent stores, like the original Dynamo, are designed to be AP systems, which is why they have things like read-repair. The requirement for "A" is that requests actually received by non-failing nodes are responded to, so as long as any replica is up, you will get a response, it's just that it may not be the consistent response.
Second, your argument about two-phase commit is combining two different arguments. First, the standard 2PC algorithm does not allow for heuristic commits. That algorithm is a CP algorithm (it is, in fact, referred to as the "unavailable protocol" by Pat Helland due to it's inability to make progress in any failure conditions). If you add in heuristic commits, then it becomes a disaster! I can imagine some situations where such a protocol would be useful, but not if you care at all about your data consistency. In that case, why use 2PC at all? Your conclusion is correct for the algorithm with heuristics: the resulting algorithm is not C or A.
Third, your confusion about CA is that you are trying to apply it to systems, like datacenters full of commodity servers and switches, that don't really fit it. Imagine, instead, a system of two computers connected by multiple, redundant NICs and cables, located next to each other and communicating by sending messages. It isn't hard to believe that you could build a system, like that, in which you could add algorithms that were CA: in other words, if someone cuts the cable, then all bets are off, but as long as those cables remain uncut, the algorithm guarantees consistency and availability. A better example is cache coherency protocols in modern processors, which are incredibly complex distributed algorithms working on CPUs that communicate over tightly integrated channels. Cache coherency protocols need to be CA, of course! If you somehow managed to severe the communication links without destroying the motherboard, you could break the algorithms assumptions, but that wouldn't make it any less of a CA algorithm.
Thanks for commenting, Charles. I will have a look at the HN thread as well.
Delete> First [...] you don't actually define the semantics
This part looks only at a partition between the web server and the data store.
Partitions within the data store are looked at here: http://blog.thislongrun.com/2015/04/cap-availability-high-availability-and_16.html
> Second [...] In that case, why use 2PC at all?
Heuristic decisions are in the XA standard since its first version (1991). YMMV, but they are very often used (to say the least) in 2PC production systems. See for example how Mark Little describes them: http://planet.jboss.org/post/2pc_or_3pc. Not really presented as an optional thing.
It shows traditional databases are not that 'CP at all cost' when it comes to managing failure.
> Your conclusion is correct [...] the resulting algorithm is not C or A
Yeah... I see 2PC as not partition-tolerant as a partition breaks acid-atomicity. Once partition intolerance is accepted, CA fits well: 2PC is consistent & available until there is a partition. Saying '2PC is not consistent and not available but is partition tolerant' is not false technically but it's a much less accurate description.
> Third [...] datacenters full of commodity servers [...]
> redundant NICs and cables, located next to each other
> [...] It isn't hard to believe that you could build a system, like that,
> in which you could add algorithms that were CA
I just totally agree with you here. CAP as a categorization tool is used for all types of distributed systems, but there is a huge difference between an application built on commodity hardware running in a multi-dc config and a 2 nodes system running on redundant hardware in a single rack.
Typically, 2PC is historically used on very specific applications: few nodes, a limited number of operations between the nodes, expensive redundant hardware all over the place, limited scaling out needs (if any). Not your typical big data system.
Hi Nicolas!
ReplyDeleteI have a question regarding 2PC. Since in the case of failure your options (both clearly flawed) are:
a) blocking all resources (as historically 2PC was defined) or
b) heuristically making a decision,
why use 2PC at all? There is non-blocking alternative - 3PC, or even better solution which additionally is partition tolerant - Enhanced 3PC. Why don't just use one of them? I wish you had considered them in your article - it would be another possibility to strengthen our "CAP categorizing" skills :P
And to be clear, I have read the link you've posted above (http://planet.jboss.org/post/2pc_or_3pc). I'm fully aware of 3PC/E3PC overheads, however I'm curious about distributed aspects of using/not using those algorithms instead of 2PC.
DeleteHi Pawel,
DeleteFor the "why use 2PC at all?" I don't have a better explanation than the one given by Mark Little ("his additional overhead is not something which the majority of environments, users, use cases etc. are prepared to accept and prefer to use 2PC"). He's an expert (and his book, 'Java Transaction Processing' is really great).
I can just add that these protocols are very complex to implement so people tend to be very conservative. A battlefield proven implementation of an average protocol is safer than a fresh new implementation of a theoretically better protocol. I'm not sure that the decision is always very rational.
For 3PC from a CAP point of view, I'm not sure. Henry Robinson shows a scenario leading to an inconsistency (http://the-paper-trail.org/blog/consensus-protocols-three-phase-commit/). If he is right (and he is usually right) 3PC is CA... It's a very good question anyway: someone using 3PC must know if it can lead to inconsistency or blocking scenarios.